frommathimportlog10,sqrtfromdatetimeimportdatetime,timedeltaepoch=datetime(1970,1,1)defepoch_seconds(date):"""Returns the number of seconds from the epoch to date. Should match the number returned by the equivalent function in postgres."""td=date-epochreturntd.days*86400+td.seconds+(float(td.microseconds)/1000000)defscore(ups,downs):returnups-downsdefhot(ups,downs,date):return_hot(ups,downs,epoch_seconds(date))def_hot(ups,downs,date):"""The hot formula. Should match the equivalent function in postgres."""s=score(ups,downs)order=log10(max(abs(s),1))ifs>0:sign=1elifs<0:sign=-1else:sign=0seconds=date-1134028003returnround(sign*order+seconds/45000,7)
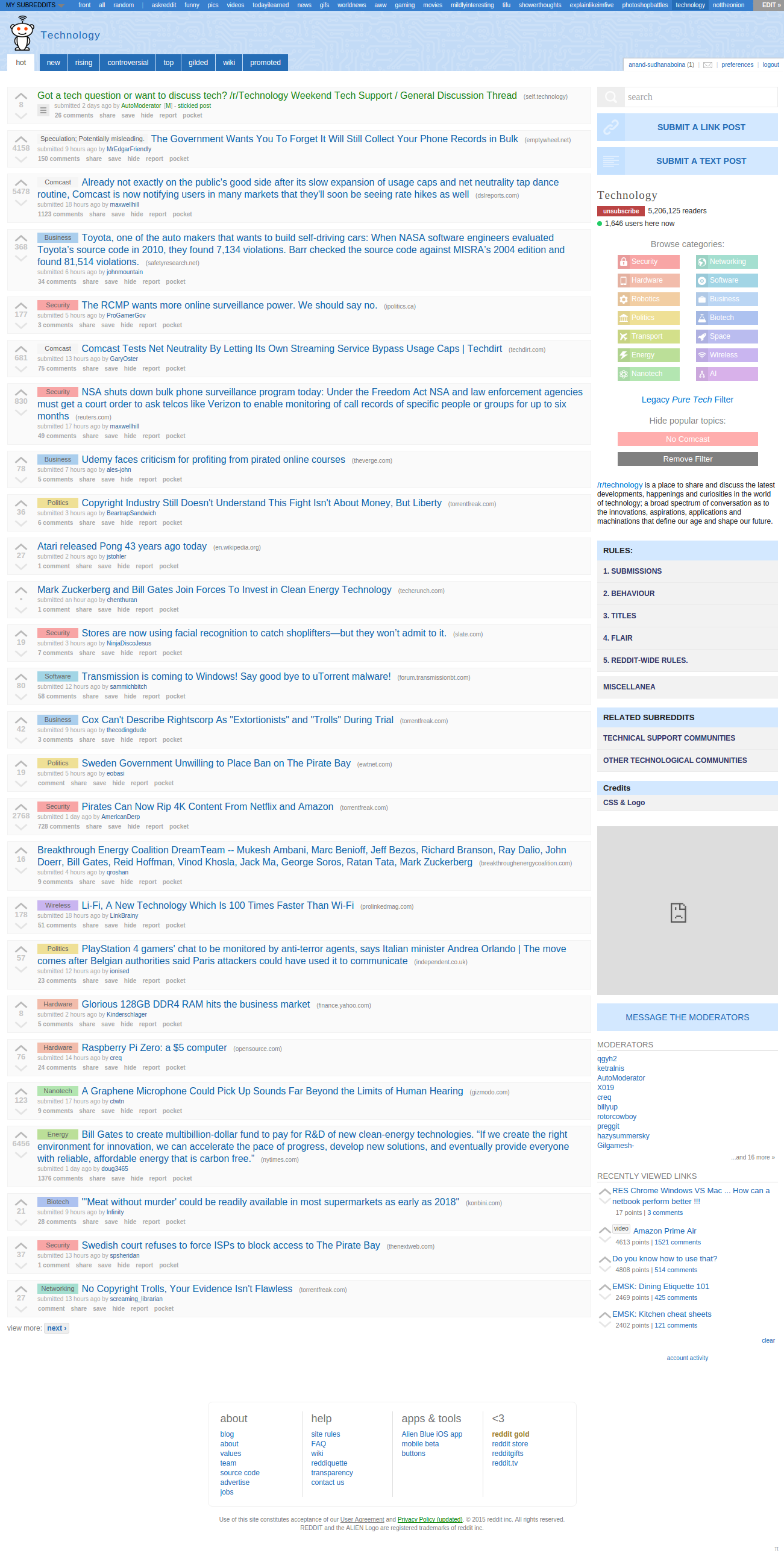
This seems very exciting, so I’ve decided to use Reddit search api to get the JSON of a day’s data, then run the algorithm with the data and see if i can see the same front page of the Reddit. Entire day’s data would be huge so I’ve decided to go with a subreddit, I choose /r/technology. I have the JSON data using Reddit search API and taken a screenshot of /r/technology to compare the results.
fromredditimport*importjson# Load the data:posts=Falsewithopen("data.json")asfile:posts=json.load(file)# Out JSON variable:outJson=[]# Iterate and claculate the hot score:forchildreninposts:forpostinchildren:downs=post["data"]["downs"]ups=post["data"]["ups"]title=post["data"]["title"]created=datetime.fromtimestamp(int(post["data"]["created"]))hotScore=hot(ups,downs,created)out={}out["title"]=titleout["hotScore"]=hotScoreoutJson.append(out)# Sort based on hotScoredefsortScore(json):try:returnint(json['hotScore'])exceptKeyError:return0outJson.sort(key=sortScore,reverse=True)# Print JSON of top 25 posts:printjson.dumps(outJson[0:25])
But there is one big challenge, Reddit does not reveal the no of down votes, neither in website nor API, so the generated results match closely but not exactly with the screenshot.
{kind=link}